Questions
- How to represent communication events as graphs?
Objectives
Learn about event graphs.
-
Learn about quantification of event graphs similarity.
Graphs
Graphs can be used to represent various types of data and relationships.
They are commonly used in computer science and related fields to model and solve problems in areas such as network analysis, social network analysis, routing algorithms, and more.
When it comes to representing MPI (Message Passing Interface) communications using graphs, the graph structure can be used to depict the communication patterns between processes in a parallel computing system. In MPI, processes communicate with each other by sending and receiving messages.
Representation of MPI communication events to graphs can be done by defining following graph attributes:
- Nodes: MPI processes
- Edges: Communication between Processes
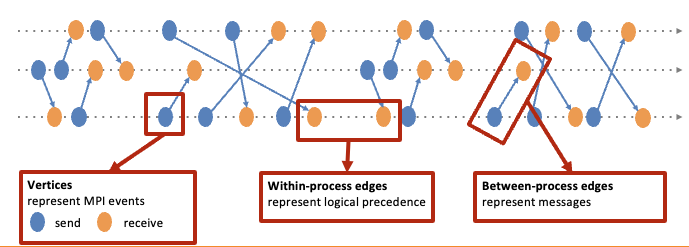
Representation of massing passing events as graphs.
The diagram above illustrates an event graph depicting the execution of a basic MPI code across three processes. Various MPI events, such as send and receive operations, are represented as blue and orange nodes respectively. The graph also displays interprocess and intra-process communication events as directed edges.
Event Graphs
In this figure, we consider a simulation across three processors, each represented by a row in the graph.
Processor 1 is the top row, Processor 2 is the middle row, and Processor 3 is the bottom row.
The vertices in each row represent the send and receive MPI functions in each processor.
Two vertices are connected if they are consecutive operations in the same processor or sent/received message to another processors.
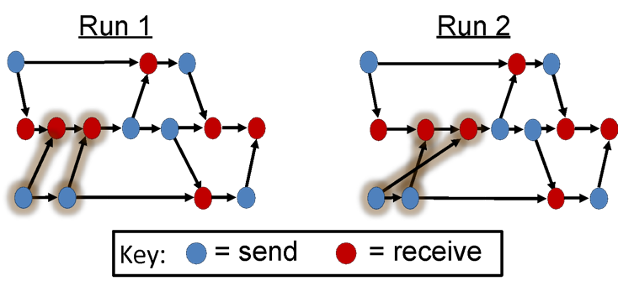
During Run 1, the first event in Processor 3 sends a message that is received as the second event in Processor 2,
and the second event in Processor 3 sends a message that is received as the third event in Processor 2.
On the other hand, during Run 2, the first event in Processor 3 sends a message that is received
as the third event in Processor 2, and the second event in Processor 3 sends a message that is received
as the second event in Processor 2.
Thus the two different runs result in event graphs of different structures.
Graph Similarity Quantification
Graph Kernels
Graph Kernels are a family of methods for measuring the structural similarity of graphs. ANACINX leverages Graph kernels to quantify (dis)similarity of event graphs that model multiple runs of a target application, Thereby quantifying the degree to which non-determinism manifests in the application.
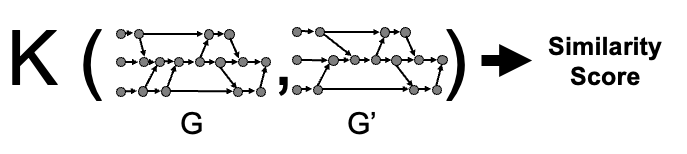
Formally, a Graph Kernel is a function:
K: G x G → ℝ+ U {0} where G denotes a set of graphs.
ANACIN-X uses graph kernel defined as:
K (G,G′) = < Φ(G), Φ(G′) >
Notations
GA set of graphs.
Φ(G)The embedding of G in a specific kind of vector space.
K(G,G′)Kernel Similarity, value of the inner product of the embeddings of G and G′ in the vector space.
Also
The Kernel Similarity, K, suffices to treat a graph kernel as a function that counts matching substructures of some kind (e.g., subtrees) of two graph to quantify how similar they are.
We use positive difinite graph kernel metric called Graph Kernel Distance that describes how far apart a pair of graphs are from each other and is given by:
dK (G,G′) = √ K(G,G′) + K(G′,G′) - 2K(G,G′)
Here, K(G′,G′) and K(G,G) represent the self-similarites of G and G′ respectively, and K(G;,G′) represents their cross-similarity.
Event Graph Labeling
We enrich our event graph construction by associating labels to vertices that have semantic relevance for communication non-determinism, as shown in Figure.
ANACIN-X uses two types of labeling that serve different functions:
- Labels to Identify Type of non-determinism:
Vertex labels enhance the WLST kernel's ability to differentiate event graphs with similar structures but different non-deterministic behaviors. They offer vital information, especially when subtle differences in message order occur between runs.
ANACIN-X supports three types of vertex labels:- Process IDs help detect variations in a process's neighbors across runs caused by non-determinism.
- Logical Timestamps enables the WLST kernel to take into account the history of data flow from one process to another over the course of execution.
- Logical Ticks help WLST kernel to detect run-t-run difference in terms of patterns of message lateness
- Labels to Identify Causes of non-determinism:
ANACIN-X uses vertex labeling in the graph model to link runtime non-determinism to specific causes in the application source code. This is done by analyzing callstack labels, representing paths in the function call graph. Aggregating these callstacks in regions of interest identifies the "hot paths" of non-deterministic communication patterns.